
Tecnologia
No mundo da tecnologia, existem detalhes muito importantes de como as informações são processadas e armazenadas na memória dos dispositivos. Computadores, celulares, tablets, TVs e outros com sistemas operacionais e memória, utilizam a chamada "codificação". Quer saber mais? Entenda a seguir.
 |
[Codificação. Imagem: Markus Spiske / Pexels | Reprodução] |
DEPOIS, VOCÊ PODE LER TAMBÉM
» Quais as funções dos hardwares de memória e dos sistemas operacionais?
» O que veio antes do streaming? E depois?
» Transformando um HD interno em externo
OS CARACTERES
Cada símbolo tipográfico usado para escrever texto numa determinada língua é um caractere, além de símbolos especiais. Vejamos alguns caracteres:
4 M / ! 8 đ ƙ s U ð q p ĉ ţ ⅘ ⁿ ⅝ æ
Em cada língua são usados vários caracteres. Português e Inglês usam cento e vinte e sete e inglês noventa e quatro, por exemplo. O número se torna maior porque temos outras línguas envolvidas e também existem caracteres científicos tais como os símbolos matemáticos (integral, congruência, vetor, etc.).
CARACTERES REAIS VERSUS ARMAZENAMENTO DE COMPUTADOR
O caractere é o que vemos e usamos na vida real, o que precisa aparecer visualmente nos nossos textos, mas não é o que o computador armazena diretamente. É por isso que existem os esquemas de codificação, onde existe um número associado a um caractere.
Esse número, por sua vez, não é armazenado em sua forma decimal. Os computadores trabalham em base 2, ou seja, em zeros e uns, então o armazenamento do caractere será dessa forma, usando um byte.
TABELA ASCII
A ASCII é o Código Padrão Americano para o Intercâmbio da Informação, que é um sistema de codificação. Em sua primeira versão, sete bits eram ocupados e o outro ficava livre, para registros como erros de transmissão. Isso levava ao limite de cento e vinte e oito caracteres.
Veja os caracteres da ASCII:
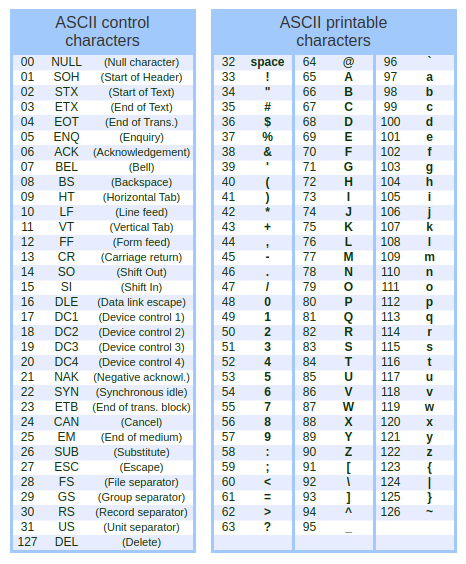 |
[Codificação ASCII. Imagem: Treinaweb | Reprodução] |
Nem tudo em nossa língua poderia ser representado, na falta de sinais diacríticos. Vamos pensar num caractere, como o "a" (minúsculo). Na ASCII, seu código é o número 97. Internamente, o computador vai armazená-lo como 01100001. Assim como na base dez, cada número é um produto de potências de dez, esse número em base dois será o produto de valores em potências versus a posição deles. Vamos ver se esse armazenamento bate?
0 • 2⁷ + 1 • 2⁶ + 1 • 2⁵ + 0 • 2⁴ + 0 • 2³ + 0 • 2² + 0 • 2¹ + 1 • 2⁰ = 2⁶ + 2⁵ + 2¹ = 64 + 32 + 1 = 97.
Nos anos 1960, passou-se a usar todos os bits, fazendo com que 256 caracteres pudessem ser representados:
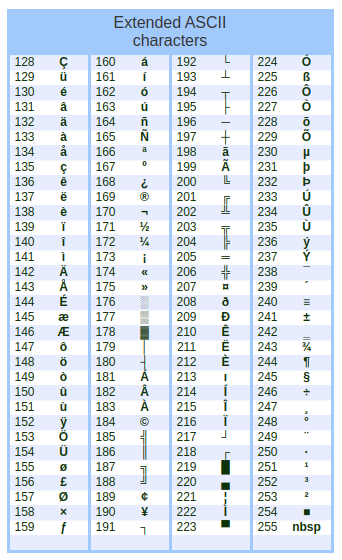 |
[Codificação ASCII extendida. Imagem: Treinaweb | Reprodução] |
Ainda assim, a ASCII não representa caracteres de outras línguas, tais como hebraica, japonesa, grega, dentre outras. Alguns símbolos do latim também não são incluídos.
No início dos anos 1990, surgiu um movimento na internet para uma codificação padronizada, independentemente de idioma. Nisso surgiu o Unicode, cujos primeiros cento e vinte e oito caracteres são correspondentes ao ASCII.
UNICODE
Hoje, o Unicode é o esquema de codificação mais utilizado. Sua estrutura é descrita na norma internacional ISO 10646. O prefixo "uni" vem do latim "um", que traz a ideia de um padrão universal.
A base do sistema foi o ASCII, porém corrigindo suas limitações e permitindo codificar um número gigantesco de caracteres, inclusive emojis. O Unicode pode usar mais de oito bits, compreendendo dezesseis e até trinta e dois, o que permitiria dois bilhões de caracteres distintos. O emoji 😍 vai ocupar quatro bytes ou trinta e dois bits, por exemplo.
O código específico do Unicode é chamado de code point, com formato U+<código hexadecimal> variando de U+0000 a U+10FFFF. Vamos ver como ficam alguns caracteres representados em Unicode e ASCII:
|
Unicode |
ASCII (decimal) |
Caractere |
|
U+0021 |
33 |
! |
|
U+0024 |
36 |
$ |
|
U+0026 |
38 |
& |
|
U+002A |
42 |
* |
Essa listagem é apresentada na Wikipedia ou outros sites especializados no tema. Assim como no ASCII, vimos existir o code point ou ainda um número para identificar cada caractere. Considerando números decimais, parte do Unicode seria assim:
|
número Unicode |
caractere |
|
33 |
! |
|
34 |
" |
|
45 |
- |
|
57 |
9 |
|
65 |
A |
|
66 |
B |
|
97 |
a |
|
98 |
b |
|
126 |
~ |
|
192 |
À |
|
227 |
ã |
|
231 |
ç |
|
233 |
é |
|
255 |
ÿ |
|
931 |
Σ |
|
945 |
α |
|
8212 |
— |
|
8220 |
“ |
Mas a codificação verdadeira envolve o formato U+hexadecimal. Vendo os mesmos caracteres da lista anterior:
|
Unicode |
caractere |
|
U+0021 |
! |
|
U+0022 |
" |
|
U+002D |
- |
|
U+0039 |
9 |
|
U+0041 |
A |
|
U+0042 |
B |
|
U+0061 |
a |
|
U+0062 |
b |
|
U+007E |
~ |
|
U+00C0 |
À |
|
U+00E3 |
ã |
|
U+00E7 |
ç |
|
U+00E9 |
é |
|
U+00FF |
ÿ |
|
U+03A3 |
Σ |
|
U+03B1 |
α |
|
U+2014 |
— |
|
U+201C |
“ |
UTF-8
No UTF-8, o número de bytes não é fixo, indo de um a quatro bytes. É o esquema de codificação multibyte mais usado, tendo como início os cento e vinte e oito caracteres do ASCII, com 1 byte cada. Veja uma pequena lista:
|
Unicode |
código UTF-8 |
hexa |
|
|
U+0021 |
! |
00100001 |
0x21 |
|
U+0022 |
" |
00100010 |
0x22 |
|
U+002D |
- |
00101101 |
0x2D |
|
U+0039 |
9 |
00100111 |
0x39 |
|
U+0041 |
A |
01000001 |
0x41 |
|
U+0042 |
B |
01000010 |
0x42 |
|
U+0061 |
a |
01100001 |
0x61 |
|
U+0062 |
b |
01100010 |
0x62 |
|
U+007E |
~ |
01111110 |
0x7E |
|
U+00C0 |
À |
11000011 01000000 |
0xC380 |
|
U+00E3 |
ã |
11000011 10100011 |
0xC3A3 |
|
U+00E7 |
ç |
11000011 10100111 |
0xC3A7 |
|
U+00E9 |
é |
11000011 10101001 |
0xC3A9 |
|
U+00FF |
ÿ |
11000011 10111111 |
0xC3BF |
|
U+03A3 |
Σ |
11001110 10100011 |
0xCEA3 |
|
U+03B1 |
α |
11001110 10110001 |
0xCEB1 |
|
U+2014 |
— |
11100010 10000000 10010100 |
0xE28094 |
|
U+201C |
“ |
11100010 10000000 10011100 |
0xE2809C |
Essa lista completa também pode ser encontrada no Wikipedia ou listagens especializadas.
Vamos supor que o computador vai armazenar a palavra ação em UTF-8. Os códigos usados serão:
|
0x61 |
0xC3 |
0xA7 |
0xC3 |
0xA3 |
0x6F |
|
a |
ç |
ã |
o |
||
Letras com sinais diacríticos do português recebem código UTF-8 com 2 bytes. O primeiro é o OxC3 (195 na notação decimal)
Como o número de bytes não é fixo, a decodificação exige que os primeiros bits informem o espaço ocupado. Se o primeiro bit é zero, e o primeiro byte é menor do que 128, esse é o único byte do caractere. Se o primeiro byte fica entre 192 a 223, são dois bytes, e assim por diante.
QUAL A CODIFICAÇÃO USADA EM MEU ARQUIVO?
Difícil saber qual a codificação usada sem algum detalhe no arquivo. Há utilitários como o file, que permitem ver com alguma precisão dizer qual a codificação.
Sabendo qual é, existe o aplicativo iconv, para converter de um esquema para outro. Um ISO-LATIN1 pode ser transformado para UTF-8, por exemplo.
ASC-II NOS NOVOS CNPJs
Os CNPJs irão mudar e, dentro disso, saíram apenas dos códigos decimais e foram para o hexadecimal, com caracteres da codificação ASCII. Entenda como vai funcionar em 👇🏻:
□
E AINDA MAIS PARA VOCÊ:
GOSTOU DESSA POSTAGEM ☺? USANDO A BARRA DE BOTÕES, COMPARTILHE COM SEUS AMIGOS 😉!




{kind=link}
0 Comentários
Seu comentário será publicado em breve e sua dúvida ou sugestão vista pelo Mestre Blogueiro. Caso queira comentar usando o Facebook, basta usar a caixa logo abaixo desta. Não aceitamos comentários com links. Muito obrigado!
NÃO ESQUEÇA DE SEGUIR O BLOG DO MESTRE NAS REDES SOCIAIS (PELO MENU ≡ OU PELA BARRA LATERAL - OU INFERIOR NO MOBILE) E ACOMPANHE AS NOVIDADES!